Mock testing, also called mocking, is an integral part of the embedded software development process as it allows you to test your code without relying on actual hardware. This can be extremely helpful when trying to debug your code or test new features.
During fuzzing testing, applications are tested using unexpected or invalid inputs. Modern fuzzers generate these inputs based on feedback about the SUT’s interaction with previous test inputs. This feedback - also called fuzz data - is then used to refine test inputs to find more bugs.
In this blog, I will show you how to combine these to approaches is a very good idea. Learn how to uncover security and functionality issues by enhancing your mocking setup with fuzz data.
.webp?width=1200&height=642&name=michael-dziedzic-XSzA_rJ8thc-unsplash%20Kopie%20(1).webp)
What is Mocking/Mock Testing?
Mock testing is a technique during which the behavior of real objects is simulated through software. Mock testing allows developers to focus on testing the functionality of a piece of code rather than its dependencies. Replacing real hardware with simulated hardware allows for testing of code without relying on actual hardware.
Let’s say you wanted to reach a specific state machine for a tested function that requires input data in a specific order from another unit. In this case it would make sense to mock the unit, as it would have to be able to process data and feed it back to the function under test.
Mocked units are typically created by the tester themselves. Sometimes, software libraries can be used to create a mocked object. These libraries provide the functionality of the hardware that is simulated. For example, if you're mocking an I/O device, then there would be a library that provides the functions for reading and writing data from it.
Using a mocked device has several advantages over using actual hardware:
- It's usually much cheaper.
- Mocked devices are easier to configure than actual hardware(especially when using a library)
- The configuration of a mocked device can be changed quickly, which is especially helpful during debugging.
- Mock testing can be done before integrating the software into the hardware.
Mock Testing With Fuzz Data: No Hardware Needed
Generally, mock testing is done with hardware-dependent functions returning static values.
By enhancing such an approach to generate return values based on fuzz data, it can incorporate runtime context, i.e., information about a system's behavior given specific test inputs. This way, you can test for positive and negative criteria, i.e., unexpected inputs (How does the program behave if values are fed in a different order than expected? How does it behave if no values are sent at all?).
To gather fuzz data, your system has to be instrumented first. This allows it to process information about previous test inputs to generate new inputs that cover more code. Instrumentation also allows you to observe how much code is covered during a test.
Another way to generate fuzz data is by leveraging the API documentation to create tests that exercise all of the different inputs and outputs of an API.
Why Coverage Feedback Is So Effective
Coverage-guided or feedback-based fuzz testing approaches use instrumentation to insert special hooks into the target program. These hooks collect information about the program's execution and send it back to the fuzzing engine. The fuzzer then uses this feedback to generate new test inputs that can traverse larger parts of the codebase and thereby trigger more interesting program states. This feedback loop allows modern fuzzers to achieve high code coverage rates.
Opposed to traditional fuzzing approaches, which basically fire random or predefined test inputs into a system randomly, feedback-based fuzzers can pin down bugs much more accurately.
An example: Imagine you have a target program that reads data from a file. A feedback-based fuzzer would insert a hook at the beginning of the file-reading function. This hook would collect information about the file format and send it back to the fuzzer. The fuzzer would then use this information to generate new test inputs that are more likely to trigger bugs in the file-reading function.
Feedback-based fuzzing has several advantages over other types of fuzzing:
- It can generate test inputs that are specifically tailored to execute certain parts of the system under test. This means that more effective tests can be generated in less time
- Feedback-based fuzzing can improve code coverage by identifying areas of the system under test that are not being exercised by the current test suite
- It can find hard-to-reach bugs by exploring areas of the system under test that are inaccessible with the starting set of inputs
Negative Testing With Fuzz Data
Fuzzing is particularly good for negative testing, a type of software testing that focuses on finding bugs by providing invalid or unexpected input to a program. This is because it can come up with test inputs that positive test forms such as unit tests often do not consider. For instance, “does a system send an error notice when I enter something sketchy?” Or, more specific to embedded code, “is a system fail-safe?”. That is, do the other modules operate safely when one module fails? Negative testing is often used to stress test programs and find edge-case bugs that can lead to undesired behavior or even exploits.
For example, imagine you have a web application that takes user input and displays it on a webpage. A negative tester might provide invalid input (e.g., HTML code) to test how the application handles such input. If the application does not sanitize user input correctly, an attacker could exploit this flaw to inject malicious code into the webpage, leading to serious security vulnerabilities.
Alternatively, imagine you are testing an API that takes a user's zip code as input. The API documentation might specify that only 5-digit zip codes are allowed. However, if you provide a 9-digit zip code as input, the API might accept it without performing any validation checks. You can then use this information to create a fuzz test that provides invalid zip codes as input to trigger bugs in the API's input validation logic.
Leveraging the API Documentation to Generate Fuzz Tests
As indicated earlier, API documentation is an excellent source of structured inputs to come up with test harnesses automatically. Often, embedded software development teams have soe form o API documentation readily available somewhere. Something as simple as the CSV table below can be enough to get a fuzzer started.
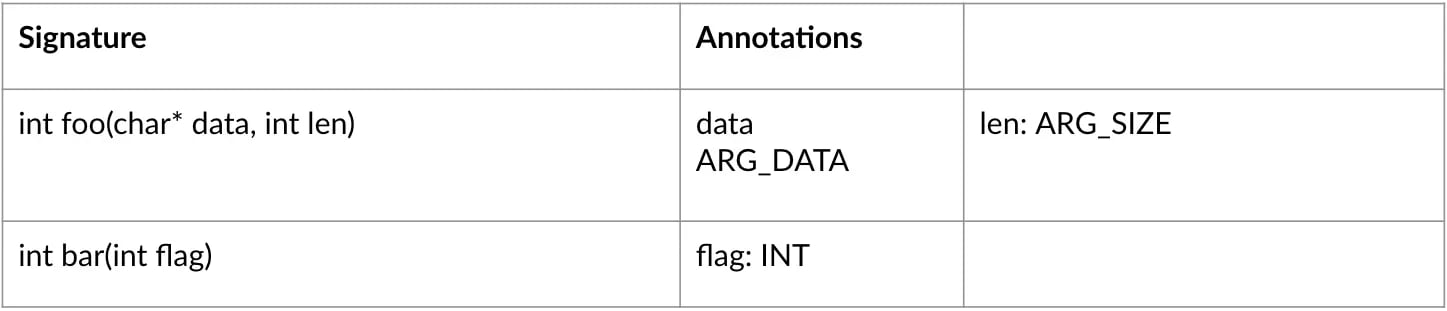
Your fuzzer will then begin by calling functions from your Public API documentation file in random order and with random parameters. It can then collect data about the covered code via instrumentation. This configuration will allow you to come up with test cases that you may not have considered that can cover vast sections of the tested code. Some open-source tools can reduce the complexity attached to fuzz testing for embedded software drastically by making it as easy as init, create and run.
Conclusion: Don't Rely On Static Return Values
Mock testing is essential to secure embedded systems. By only feeding your mocking setup with static return values, it will be very limited in the paths it can reach, as it cannot actively improve inputs to uncover new paths. By feeding the tested function with feedback-based fuzz data, you will be able to reach more code paths and thereby trigger more interesting program states and bugs.
If you're interested in learning more about fuzz data or want to get first-hand experience with fuzzing, try out our open-source fuzzing tool CI Fuzz. It allows for uncomplicated fuzz testing straight from the command line using a few simple commands. CI Fuzz allows you to have your first C/C++ fuzz tests running within a couple of minutes.
