White-box fuzz testing has proven highly effective in finding critical bugs and vulnerabilities. Tech giants like Google and Microsoft uncover thousands of issues using this method. But why doesn’t every company adopt fuzz testing as part of their testing strategy? The main barrier is the high level of manual effort and the extensive time required to properly set it up and maintain it. You first need to identify what you want to test, then implement corresponding fuzz tests, run them, and address the identified bugs. Typically, this requires a lot of manual work. However, with the rapidly improving coding and reasoning capabilities of LLMs, a large part of the process can now be automated. Let us show you how.
Step 1. How to automatically identify fuzz testing targets
Step 2. How to automatically create fuzz tests
Step 3. How to automatically run fuzz tests
Step 4. How to automate the whole fuzz testing cycle
Step 1. How to automatically identify fuzzing entry points
Once a fuzzer is connected to your source code, you can start fuzzing it to check for bugs and security vulnerabilities. The first step in this process is identifying which parts of the software you want to fuzz. The focus should be on the most critical functions or APIs that execute a significant amount of code, trigger key functionalities, and are likely to contain bugs.
Manually identifying these targets can be time-consuming and challenging, especially in large codebases or when detailed domain knowledge is lacking. This issue is common when testing or security teams operate independently of development teams.
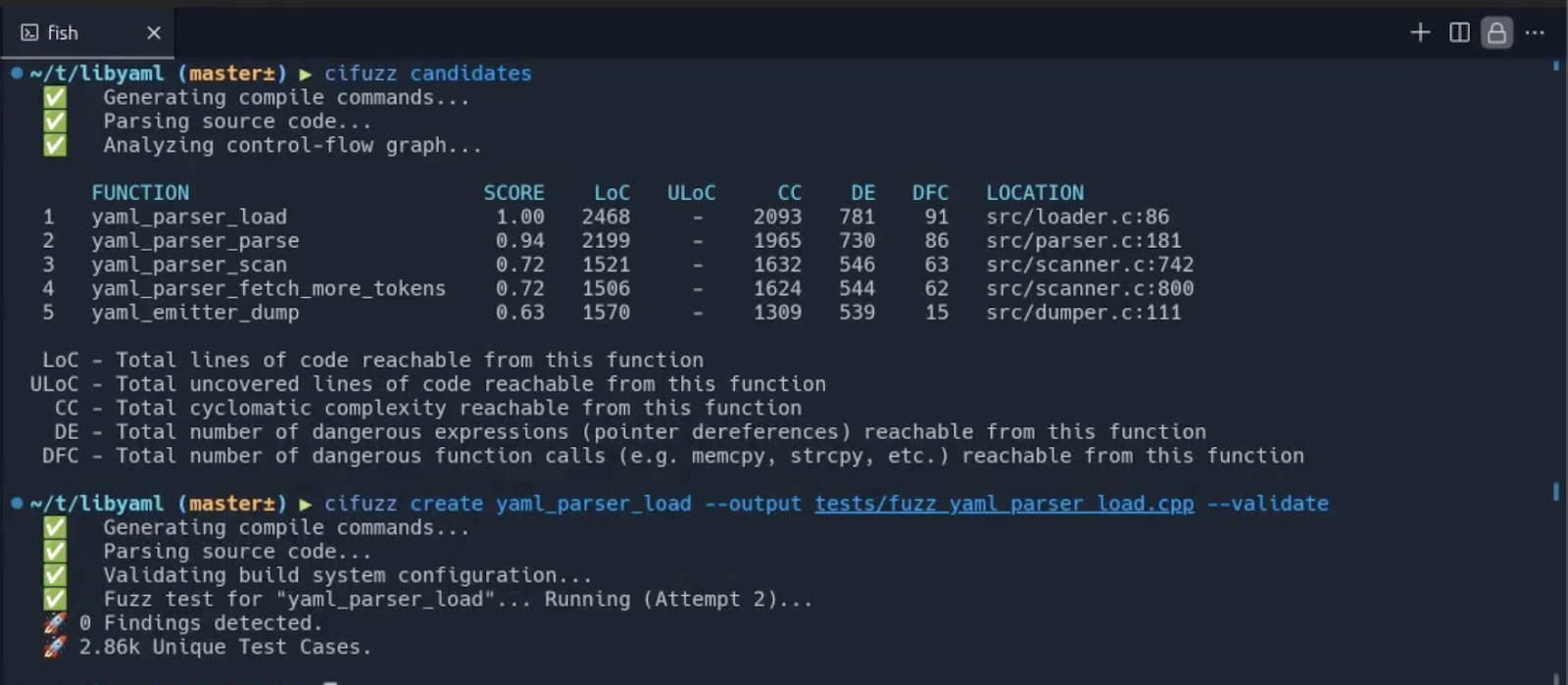
However, it can be automated using static analysis. CI Fuzz, an AI-automated fuzz testing by Code Intelligence, analyzes your source code and generates a prioritized list of the most suitable functions and APIs to fuzz. Each “fuzzing candidate” is scored based on its expected impact using four key metrics:
- Reachable code: The number of lines of code a function can reach. Testing functions that reach the most code helps achieve higher coverage with fewer tests.
- Dangerous Expressions: The number of risky expressions a function reaches, such as pointer dereferences and raw pointer manipulations. These are common sources of memory corruption bugs.
- Dangerous Function Calls: The number of calls to potentially unsafe functions like memcpy, strcpy, and memset. These are often where memory corruption bugs originate.
- Cyclomatic Complexity: Higher complexity in code generally correlates with a higher probability of bugs.

This is how the prioritization of functions to fuzz looks like in CI Fuzz
These metrics are aggregated across all reachable functions, eliminating the need for manual code review. With this approach, your code can be analyzed in just a few minutes—or even seconds—depending on its size, compared to what might otherwise take days or weeks.
Check out the 40-second demo to see how candidate selection works on LibYAML, a C library for parsing and emitting YAML.
What if we already have unit test and fuzz testing written?
In that case, let’s focus on the areas of code that haven’t been thoroughly tested yet. You can provide a coverage report to CI Fuzz to account for existing coverage from your unit tests or fuzz tests. CI Fuzz will use this information to adjust the scores of functions, prioritizing those with lower coverage.
This approach allows you to concentrate your fuzzing efforts on the parts of your code that are not yet well tested or fuzzed, thereby maximizing the impact of fuzz testing.
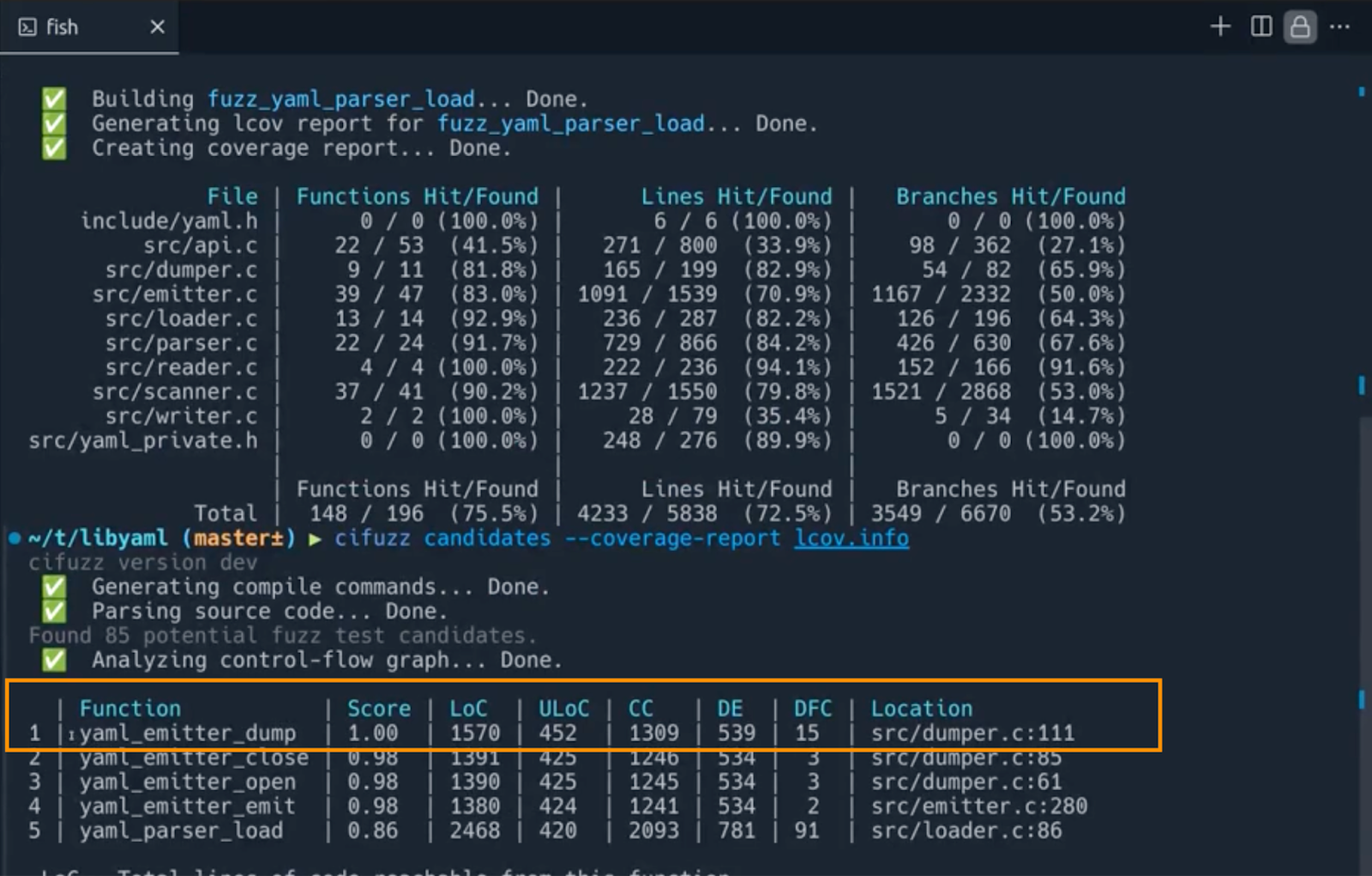
Based on the coverage report above, CI Fuzz identified functions with lower coverage.
In the previous step, yaml_emitter_dump was in fifth place, and now it’s the first to be tested.
Step 2. How to automatically create fuzz tests
Once you’ve identified what needs to be tested, the next step is to write high-quality fuzz tests that target specific functions or APIs. These tests, often called fuzz harnesses or fuzz targets, are essential for effective fuzzing. However, without insights into how different parts of the code interact or where potential vulnerabilities might exist, crafting inputs that reach deep, obscure code paths can be challenging.
𝗪𝗵𝗮𝘁 𝗱𝗼 𝘄𝗲 𝗺𝗲𝗮𝗻 𝗯𝘆 𝗵𝗶𝗴𝗵-𝗾𝘂𝗮𝗹𝗶𝘁𝘆 𝗳𝘂𝘇𝘇 𝘁𝗲𝘀𝘁𝘀?
High-quality fuzz tests are realistic tests that adhere to the API contract of the target function. They ensure the function is called in the correct context by testing various expected use cases of the API. This approach increases the likelihood of achieving high code coverage, which in turn uncovers more bugs. Like unit tests, fuzz tests should include the necessary initialization and cleanup code to avoid false positives and ensure accurate results.
And as your code evolves, you should update your fuzz tests and keep them in sync with the code they test.
Sounds like a daunting task, doesn’t it? You can automate this step by leveraging the code understanding and generation capabilities of modern LLMs. CI Fuzz uses its advanced static analysis capabilities to automatically collect the context needed to create a realistic fuzz test for a given function. This includes usage examples in the code base, e.g., unit tests. These usage examples provide valuable insights into the various workflows in which the target function is used and the correct context to call it, including the needed initialization and clean-up logic. CI Fuzz employs advanced prompting techniques such as Tree of Thoughts (ToT) to activate advanced LLM reasoning capabilities and ensure the high quality of created fuzz tests.
See how it works in the video:
Automatic refinement
Given the hallucination issues and the non-deterministic nature of LLM responses, CI Fuzz features automatic refinement and fixing steps to verify that the created fuzz tests can be built and run successfully. To this end, CI Fuzz first tries to build the created tests and automatically analyzes and fixes any build errors. At a high level, build errors are analyzed using LLM, and the analysis results are used to create a refined version of the fuzz test.
CI Fuzz then runs the fuzz test and performs a health check that includes checking that the fuzz test does not crash immediately and gains code coverage. If the fuzz test doesn’t pass this health check, CI Fuzz will analyze the underlying issue and further refine the test.
Watch the video to see the code coverage results and see the step-by-step process:
Interactive mode
If the automatic refinement fails to create a working fuzz test, CI Fuzz has an interactive mode that enables users to intervene to provide additional hints. These hints can be persisted so that CI Fuzz can leverage them when generating the next tests. This also provides a general mechanism for users to provide their domain knowledge to CI Fuzz to improve the quality of created fuzz tests. See how it works in the video below:
Step 3. How to automatically run fuzz tests
When it comes to running tests, you may face a few challenges: - Configuring compiler flags for code coverage and sanitizer instrumentation is manual and requires knowledge of the underlying fuzzing engine.
- You need to determine how long to run fuzz tests or when to stop them based on diminishing returns.
- Reporting code coverage achieved by fuzz tests is often a manual process.
CI Fuzz automatically sets the compiler flags needed to add coverage and sanitizer instrumentation, which are needed by the underlying fuzzing engine, e.g., libFuzzer and AFL++. It executes fuzz tests while monitoring their progress, allowing users to set custom runtime criteria, such as a maximum runtime or running tests until no new coverage is achieved within a specified time window.
Discovered issues are saved with additional details, including their severity.
CI Fuzz also supports regression testing by running tests against the existing corpus and previously identified crashing inputs. Additionally, it reports the overall code coverage achieved by the executed fuzz tests.
Step 4. How to automate the whole fuzz testing cycle
At Code Intelligence, we’re on a mission to lower barriers to fuzz testing, and that’s why we made it possible to run all three previous steps with a single command. There is no need to analyze the code base, write and build tests—CI Fuzz can do it all for you; just let it know when to stop. For that, you can use the desired code coverage rate - let it be 60, 70, or 90%, depending on how thoroughly you want your code to be tested.
One more great benefit is that you don’t need to have deep code understanding anymore to write high-quality fuzz tests and find bugs and vulnerabilities. So, this is how you can do fuzzing now:
- Set up a testing goal - how much code coverage you want to achieve
- Run one command
- Get information about findings.
.gif?width=1083&height=632&name=Spark%20demo%20(cropped).gif)
Learn more about how fully automated fuzzing works in this blog post.